人才强校 | 中国农大薛一鸣、文娟课题组在信息安全领域取得新进展
中国农大新闻网讯 6月27日至28日,第10届美国计算机学会信息隐藏和多媒体安全研讨会(10th ACM Workshop on Information Hiding and Multimedia Security,ACM IH&MMSEC'22)在美国加州圣巴巴拉市举行。中国农大信息安全团队的两篇论文被录用,其中《基于直推式学习的领域自适应文本隐写分析》(Domain Adaptational Text Steganalysis based on Transductive Learning)获本届会议唯一最佳论文奖(Best Paper Award)。这是继2018年来中国获此荣誉后,时隔四年再次获得此项荣誉,为我国赢得赞誉。
本次研讨会共收录了18篇来自牛津大学、埃因霍温理工大学、纽约州立宾汉姆顿分校、巴黎高等电信学校、中国科学院信息工程研究所信息安全国家重点实验室等单位的研究论文。
两篇文章均针对文本隐写分析领域中存在的问题、基于人工智能理论提出了解决方案。其中《基于直推式学习的领域自适应文本隐写分析》针对现有文本隐写分析方法普遍基于有监督训练、依赖大量的有标签数据,但在实际任务中,待测未知样本往往缺少预设标签,训练集和测试集之间难以满足独立同分布的条件,导致实际隐写检测性能显著降低、模型泛化性差等问题。提出了一种适用于多源域的领域自适应检测算法。该算法通过设计分布自适应模块来获得领域无关的特征向量,并设计三种损失函数来实现领域适配,克服域不匹配问题;引入多组源域数据,并在分类边界对齐特征提取器和分类器,直接面向目标域优化网络,提高对隐写文本的检测性能。实验结果表明该框架可以有效提高对未知领域的适应性,充分利用多源域数据,为文本隐写分析中的域不匹配问题提供了解决方案,并提高了算法的通用性。

图1:基于直推式学习的领域自适应文本隐写分析模型结构
《基于注意力机制和元学习的少样本文本隐写分析》(Few-shot Text Steganalysis Based on Attentional Meta-learner)提出了一个在极少数据情况下进行文本隐写分析的元学习框架,并且可以在不同领域任务间可以实现快速适应。该模型包含一个通用的特征提取器和一个特定任务的特征提取器,二者共同学习句子表征。为了充分利用不同任务的预测结果提出了复杂的损失函数来更新元学习器,可以实现任务间的快速适应。本文为文本隐写分析中的少样本问题以及普遍适应性差的问题提供了解决方案。
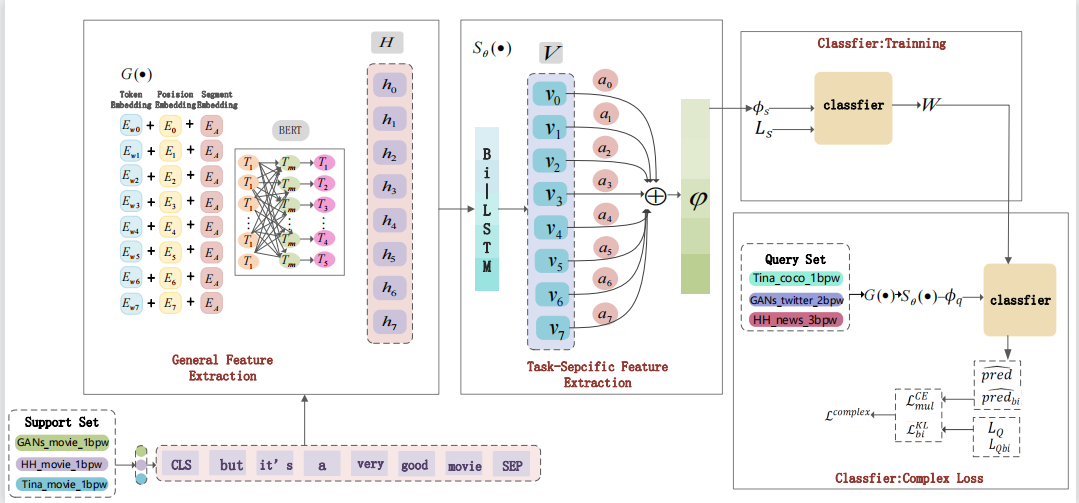
图2:基于注意力机制和元学习的少样本文本隐写分析模型结构
《基于直推式学习的领域自适应文本隐写分析》的通讯作者为文娟副教授,第一作者为薛一鸣教授,2019级硕士研究生杨博雅为学生第一作者,2018级博士生彭万里和2020级硕士研究生邓雅茜参与了工作。《基于注意力机制和元学习的少样本文本隐写分析》的通讯作者为薛一鸣教授、第一作者为文娟副教授,2021级硕士研究生张梓葳为学生第一作者,2020级硕士研究生杨雨参与了工作。
相关研究得到了国家自然科学基金项目(61872368,61802410)的支持,是中国农大计算机科学与技术一级学科在“入主流、树标杆”指引下取得的又一标志性成果。
美国计算机学会信息隐藏和多媒体安全研讨会(ACM IH&MMSEC)是多媒体安全领域的顶级国际学术会议,议题涵盖多媒体隐写与隐写分析、取证与反取证、数字水印与多媒体保护等。
原文链接:
https://doi.org/10.1145/3531536.3532963
https://doi.org/10.1145/3531536.3532949
供稿:信息与电气工程学院
供图:信息与电气工程学院
编辑:李杨
责编:于哲
